A quick walkthrough in the VMDK format
VMDK is more a set of formats rather than a unique one. Let's dive in the core principles and demystify it for forensic analysts.

After attending a conference for incident response teams, I joined a project aiming to create a forensic framework allowing acquisition and visualization of evidence from various sources: the Exhume toolkit.

In this quest of retrieving data from various base formats, I got involved in the understanding and implementation of a parser for the VMDK format.
The Virtual Machine Disk format has been created by VMware and is used by all kinds of virtual machines from all types of hypervisors. It is also used in exchange formats used to share virtual machines from one hypervisor to another.
Most IT experts, from cybersecurity to system administrators have heard of VMDK files. And I am no exception. But I never really understood what was behind this format. Sure, I did encounter some difficulties to access data from a VMDK file sourced from and ESXi server but I always found tools allowing to convert the file to a better suited format... Including VMDK itself.
At that moment I wondered why converting a VMDK file to another one could help me get access to the data for forensic purposes. And I've found the answer now I did some serious research on the matter.
A format of formats
The VMDK is not one file format by itself but rather a collection of formats depending on the configuration set up for the virtual machine. Many parameters can have an impact on the way the virtual machine data will be stored:
- Whether the disk is thin provisioned or not
- Whether the disk image is stored in a file, a full hardware disk or a partitioned disk
- Whether the disk is divided in several files or not
- Whether the data is compressed or not
- Whether the file represents a snapshot or a full disk
At the beginning, there is one thing in common for all formats: the descriptor file.
The descriptor file bears its name well and contains the metadata about a VMDK disk allowing to read and write data to the virtual disk.
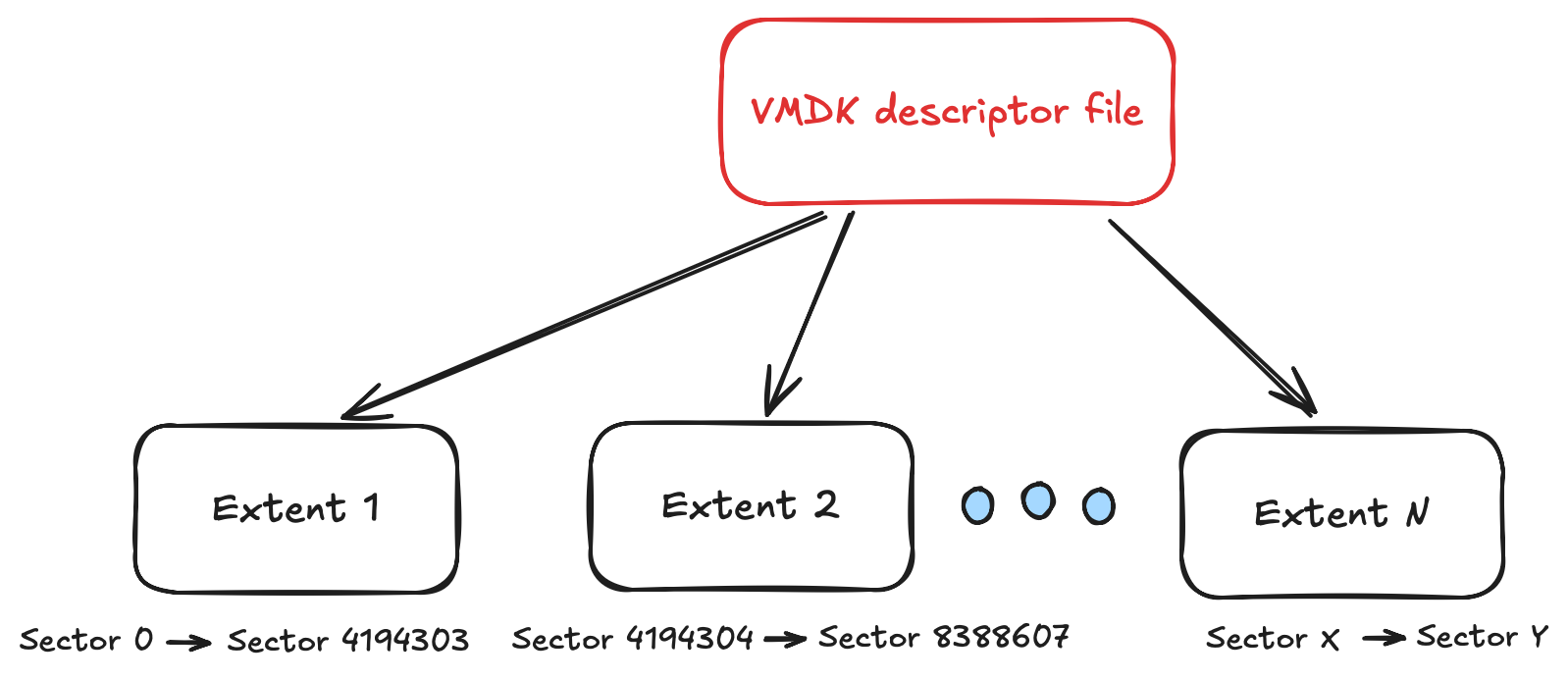
It is a text description, usually in a separate text file, of various parameters related to the disk itself: disk ID, adapter type, but most importantly a list of references to what is described as extents.
Extents are the actual files, disks or partitions containing the data on the virtual disk. They can be of various forms determined by a parameter specified on each line.
A descriptor file can look like this:
# Disk DescriptorFile
version=1
encoding="UTF-8"
CID=fffffffe
parentCID=ffffffff
createType="twoGbMaxExtentFlat"
# Extent description
RW 2097152 FLAT "Disque virtuel 2-f001.vmdk" 0
# The Disk Data Base
#DDB
ddb.adapterType = "lsilogic"
ddb.geometry.cylinders = "512"
ddb.geometry.heads = "128"
ddb.geometry.sectors = "32"
ddb.longContentID = "d0f5e5f69fcd0241f710a9dcfffffffe"
ddb.uuid = "60 00 C2 96 41 d4 0c 4b-bc 3a 43 31 4c d0 b4 09"
ddb.virtualHWVersion = "21"
The descriptor file above specifies a disk of type 2GbMaxExtentFlat. This means that the disk is built around extent files of maximum 2GB that contain the actual data in a flat manner (the disk data is stored in a raw form). The extent description section will notably describe the number of sectors of 512 bytes for each extent and the start sector of the extent (here 2 097 152 sectors starting at sector 0).
So, we have a type for the disk as a whole and a type for each extent individually. It starts with a mess for newcomers, isn't it?
I won't dive in details on disk types. Mostly they will give a bit more details on the reasons extents are segmented in a certain way (in a single file or not, full disk, partition, etc.).
What interests me the most today is the way data is stored in the extents. Extents can also be one of several types:
- Flat : the data is stored as is in the file
- Sparse : the data is stored in "grains" allowing to allocate only what's necessary
- Zero : there is no data, just zeros (in this case, no extent path is specified)
- VMFS : somewhat similar to flat but on ESXi servers
- VMFSSparse : a sparse variant for ESXi servers
- And others I won't dive in today
The VMDK descriptor is usually in the <name>.vmdk file. Extents can be in other files such as <name>-flat.vmdk, <name>-f001.vmdk, or <name>-s001.vmdk.
Let's dive in the different extent types.
Flat, VMFS and Zero
Flat and VMFS extent types are basically the same type. They store raw data in the extent. That is, if you read data at byte 0 of the first extent, you will read the first byte of the virtual disk itself.
There can be some hiccups when the disk is segmented in several files in terms of how offsets must be handled (because the file is not starting at sector 0) but that's it.
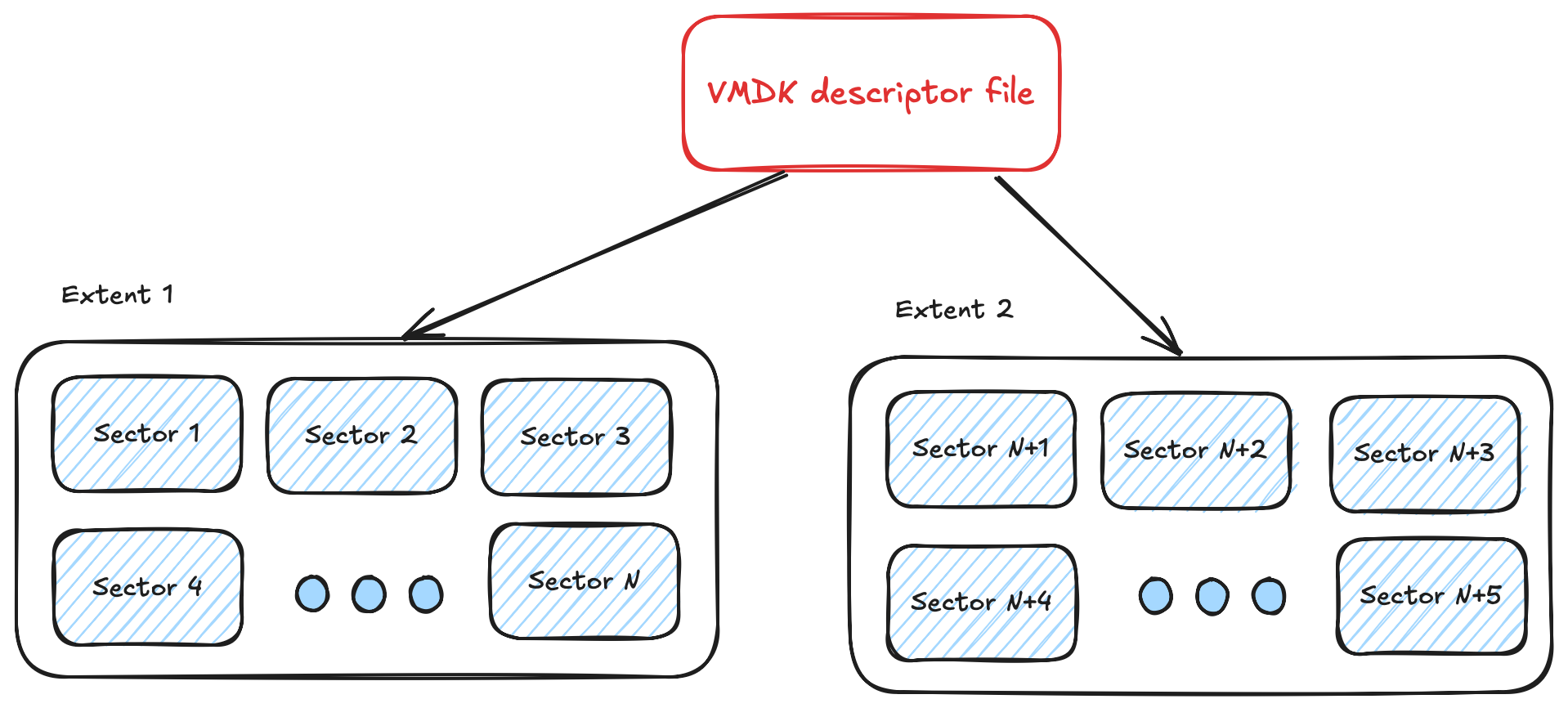
Flat and VMFS files cannot be thin provisioned and the combined size of such extents will be exactly the capacity of the disk with zeros located in places that have not been written yet. There is no header, no metadata including in the extents. Only the disk data.
Flat and VMFS files always have a separate plaintext descriptor file and are easy to identify through it as it is easy to open in a regular text editor.
The zero extent is only a virtual extent spitting out zeros.
Sparse
The sparse extent types appear when a disk is thin provisioned (when the size of the disk specified at the virtual machine creation is not fully allocated immediately).
The sparse extent files are binary files following a specific format. They start with the "KDMV" magic bytes (VDMK in little endian) and a header that will indicate the top-level metadata needed to read the file.
It is important to note that a sparse extent file is segmented in blocks of 512 bytes. As such, the header is 512 bytes long with padding to fill up the whole sector. All subsequent references in the file are specified in terms of sectors of this size.
monolithicSparse disks where the VMDK descriptor is not in a separate file but is embedded directly into the sparse extent file. In this case, the sparse file header will give the sector number where to locate the descriptor and the sector count it will takeThe header of a sparse file contains a lot of metadata related to the way the data is organized. This is necessary because the disk contents are not organized sequentially.
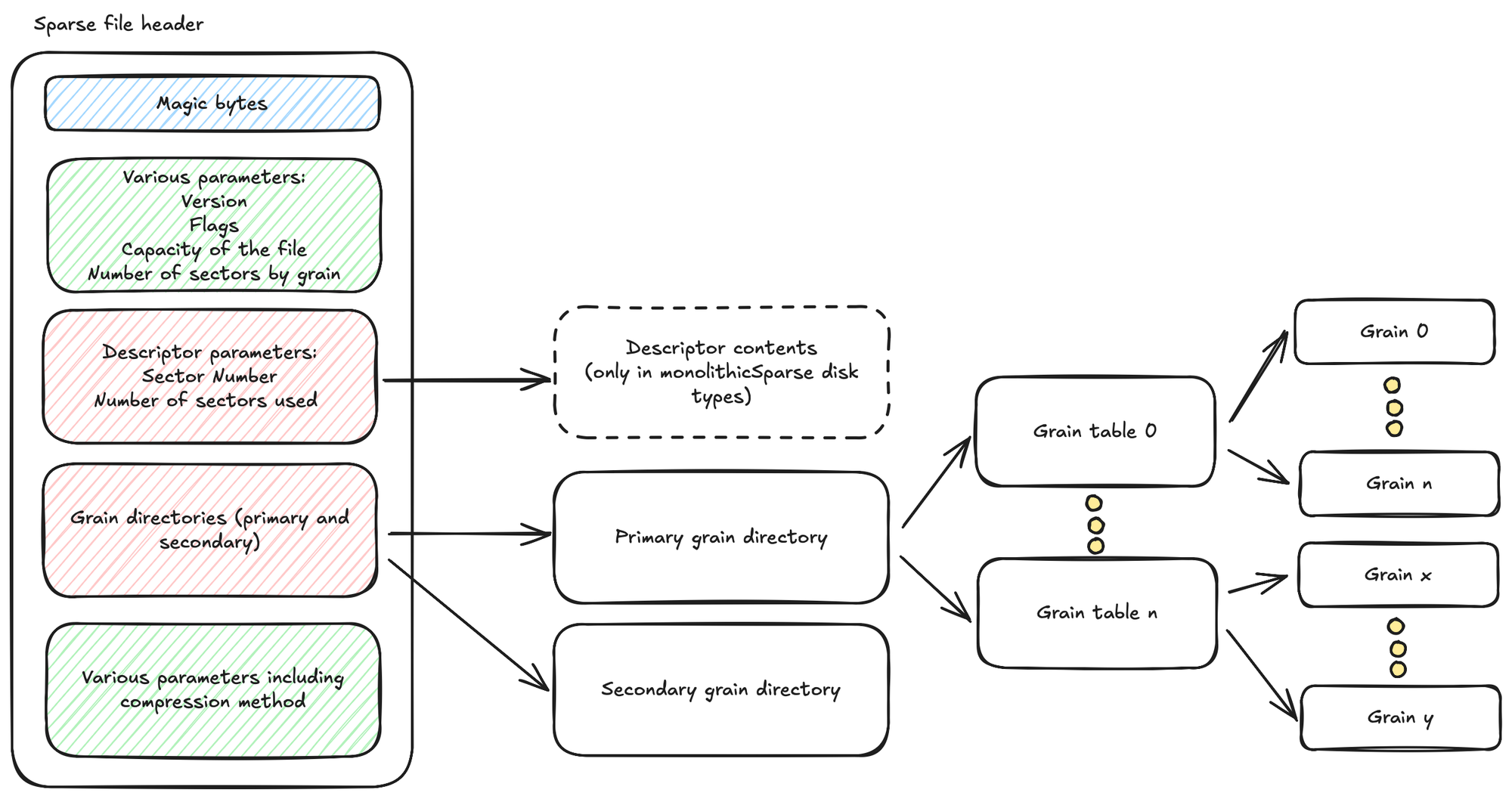
To allow full understanding of this overview, we have to dive in the nature of a grain.
A grain is a group of sectors. The number of the sectors grouped in a grain is specified by a parameter in the header (it is usually set to 128).
So, in a sparse file the disk data is split in blocks of several 512-byte long sectors. Grains in which no data has been written are not provisioned (sparse grain) in the file and the corresponding entry in the grain table is set to 0 indicating that any byte retrieved from it should be 0.
Let's talk about the grain directory and the grain table.
The grain directory is a list of sector numbers pointing to various grain tables that can be placed anywhere in the sparse file. Each grain table will point to the first sector (relative to the start of the file and not the disk in this case) of the corresponding grain in the file.
In the grain directory and grain tables, grains are sorted in the same order as on the actual disk: the first entry of the first table pointed by the directory is the first sector of the disk part sliced in this sparse file (remember that a extent file does not necessarily start at sector 0 of the disk).
All the sectors of a provisioned grain are written fully in the file. A typical example of that is the sector 0 of a disk partitioned with a Master Boot Record. The MBR is usually 512-byte long. In this case, the grain 0 is provisioned and will contain data only in the first sector. All the other 127 (in case, the grain size is 128) are often set to 0.
The primary and secondary grain directories usually exist together to ensure resiliency in case of data corruption. Despite this, there are some cases where only the secondary directory should be used. A flag indicates which on to use depending on the case.
The file format explained before has 2 other variants:
- VMFS sparse: similar to the Sparse format but with several Copy-On-Write files
- StreamOptimized sparse file: used in exchange formats such as OVA, this is a sparse file but with grain data compressed (using ZLIB DEFLATE)
In the first case, the file header format changes and contains more metadata allowing a root / children relationship between files.
In the second case, the file also contains markers that allow to read the file sequentially. It is still possible to refer to the data using the contents of the header rather than reading the whole file but it should be taken into account that a marker starts the grain and not the actual data. Moreover, even if when they are decompressed they have a fixed size, the compressed grains can be of variable length and may be the source of irregular repartition of grains in the file.
I won't dive into these special cases as they work on the same principles as the sparse extent type.
Retrieving data for forensic purposes
A challenge encountered by the forensic analyst when working with VMDK file is often to be able to retrieve the disk data in a reproducible and demonstrable way. Most forensic tools require a flat VMDK image to be able to work on the data. And you now see why this is the case.
However, flat images are not the norm as disks are most of the time thin provisioned to spare disk space on the host. This requires a conversion of the VMDK files to a monolithic flat one.
VMware (now Broadcom) provides such conversion tools but they are mostly closed source and there is no warranty of the integrity of data.
That's okay for most investigations but some require high levels of integrity.
In this case, the most sensible approach is to directly parse the original source without any attempt to convert it. This is the approach I used in my contribution to Exhume Body. It is not a complete coverage of all VMDK formats yet but feedbacks and samples will be useful for me to improve the module.
You can find the source here:
Don't hesitate to rise an issue or PR to improve this module.
A bit more documentation
https://venthusiastic.wordpress.com/2014/03/12/vmdk/